31 | 时代之风(下):HTTP/2内核剖析
Nov 14 · 10min
归纳
- HTTP/2 必须先发送一个“连接前言”字符串,然后才能建立正式连接;
- HTTP/2 废除了起始行,统一使用头字段,在两端维护字段“Key-Value”的索引表,使用“HPACK”算法压缩头部;
- HTTP/2 把报文切分为多种类型的二进制帧,报头里最重要的字段是流标识符,标记帧属于哪个流;
- 流是 HTTP/2 虚拟的概念,是帧的双向传输序列,相当于 HTTP/1 里的一次“请求 - 应答”;
- 在一个 HTTP/2 连接上可以并发多个流,也就是多个“请求 - 响应”报文,这就是“多路复用”。
链接前言
TLS 握手成功之后,客户端必须要发送一个“连接前言”(connection preface),用来确认建立 HTTP/2 连接。
这个“连接前言”是标准的 HTTP/1 请求报文,使用纯文本的 ASCII 码格式,请求方法是特别注册的一个关键字“PRI”,全文只有 24 个字节:
PRI * HTTP/2.0\r\n\r\nSM\r\n\r\n
在 Wireshark 里,HTTP/2 的“连接前言”被称为“Magic”,意思就是“不可知的魔法”。
所以,就不要问“为什么会是这样”了,只要服务器收到这个“有魔力的字符串”,就知道客户端在 TLS 上想要的是 HTTP/2 协议,而不是其他别的协议,后面就会都使用 HTTP/2 的数据格式。
头部压缩
因为语义上它与 HTTP/1 兼容,所以报文还是由“Header+Body”构成的,但在请求发送前,必须要用“HPACK”算法来压缩头部数据。
“HPACK”算法是专门为压缩 HTTP 头部定制的算法,与 gzip、zlib 等压缩算法不同,它是一个“有状态”的算法,需要客户端和服务器各自维护一份“索引表”,也可以说是“字典”(这有点类似 brotli),压缩和解压缩就是查表和更新表的操作。
为了方便管理和压缩,HTTP/2 废除了原有的起始行概念,把起始行里面的请求方法、URI、状态码等统一转换成了头字段的形式,并且给这些“不是头字段的头字段”起了个特别的名字——“伪头字段”(pseudo-header fields)。而起始行里的版本号和错误原因短语因为没什么大用,顺便也给废除了
为了与“真头字段”区分开来,这些“伪头字段”会在名字前加一个“:”,比如“:authority” “:method” “:status”,分别表示的是域名、请求方法和状态码。
现在 HTTP 报文头就简单了,全都是“Key-Value”形式的字段,于是 HTTP/2 就为一些最常用的头字段定义了一个只读的“静态表”(Static Table)。
下面的这个表格列出了“静态表”的一部分,这样只要查表就可以知道字段名和对应的值,比如数字“2”代表“GET”,数字“8”代表状态码 200。
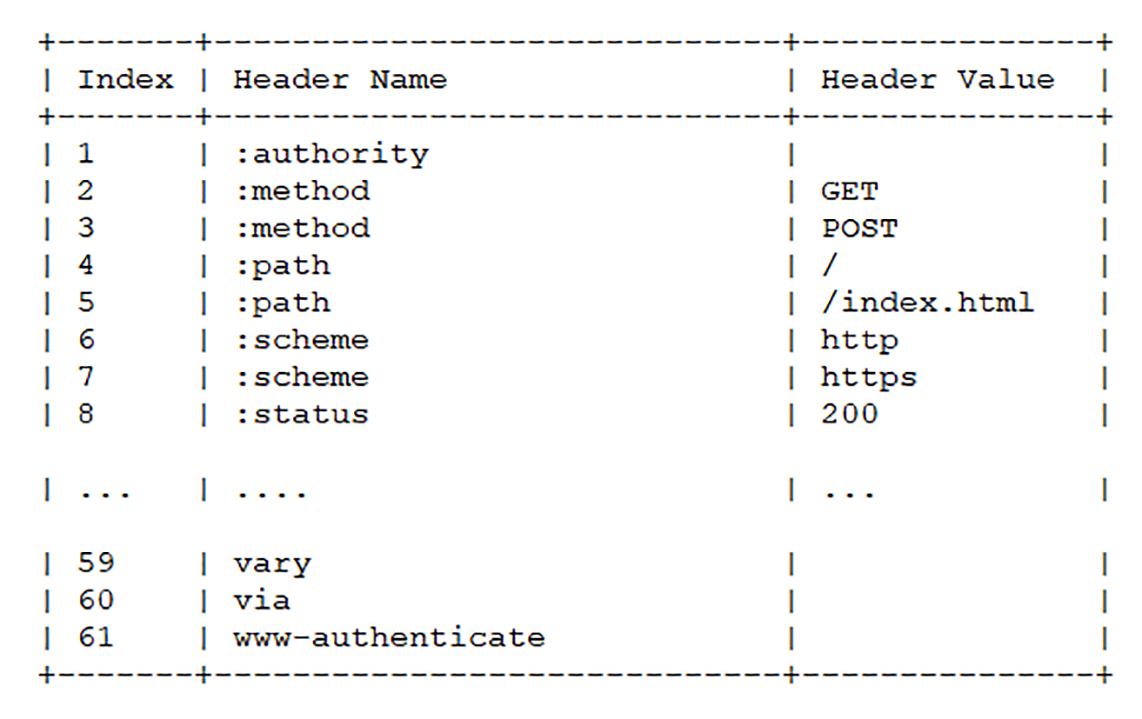
如果找不到怎么办,这就用到我们的动态表,它添加在静态表后面,结构相同,但会在编码解码的时候随时更新。
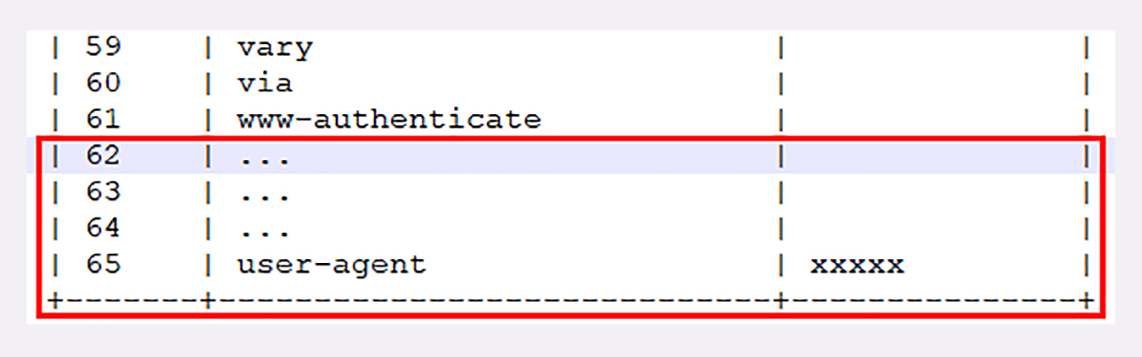
比如说,第一次发送请求时的“user-agent”字段长是一百多个字节,用哈夫曼压缩编码发送之后,客户端和服务器都更新自己的动态表,添加一个新的索引号“65”。那么下一次发送的时候就不用再重复发那么多字节了,只要用一个字节发送编号就好。
二进制帧
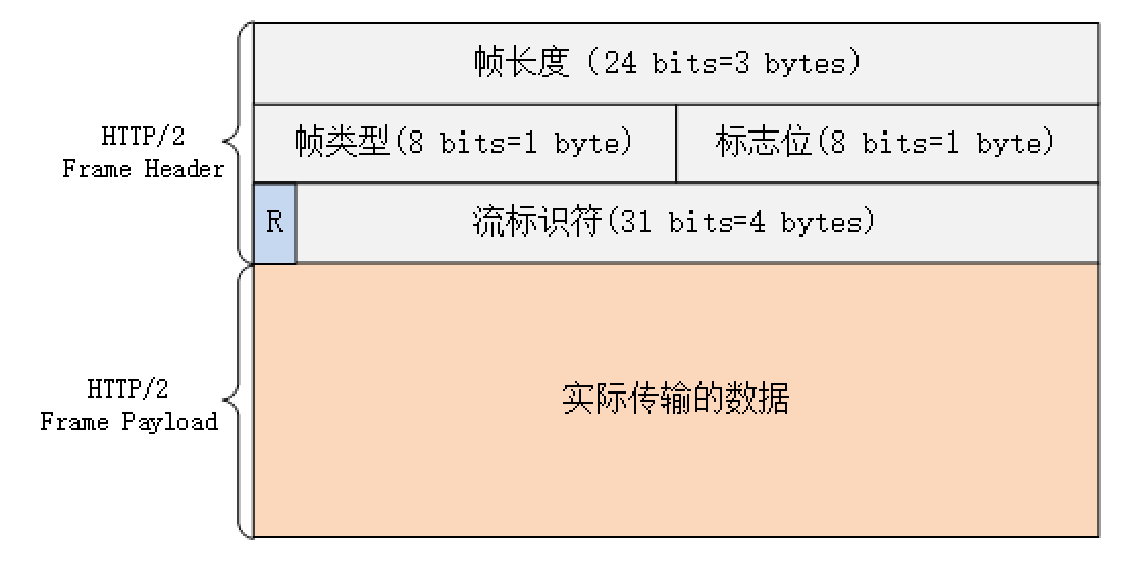
帧开头是 3 个字节的长度(但不包括头的 9 个字节),默认上限是 2^14,最大是 2^24,也就是说 HTTP/2 的帧通常不超过 16K,最大是 16M。
长度后面的一个字节是帧类型,大致可以分成数据帧和控制帧两类,HEADERS 帧和 DATA 帧属于数据帧,存放的是 HTTP 报文,而 SETTINGS、PING、PRIORITY 等则是用来管理流的控制帧。
第 5 个字节是非常重要的帧标志信息,可以保存 8 个标志位,携带简单的控制信息。常用的标志位有 END_HEADERS 表示头数据结束,相当于 HTTP/1 里头后的空行(“\r\n”),END_STREAM 表示单方向数据发送结束(即 EOS,End of Stream),相当于 HTTP/1 里 Chunked 分块结束标志(“0\r\n\r\n”)。
报文头里最后 4 个字节是流标识符,也就是帧所属的“流”,接收方使用它就可以从乱序的帧里识别出具有相同流 ID 的帧序列,按顺序组装起来就实现了虚拟的“流”。
流标识符虽然有 4 个字节,但最高位被保留不用,所以只有 31 位可以使用,也就是说,流标识符的上限是 2^31,大约是 21 亿。
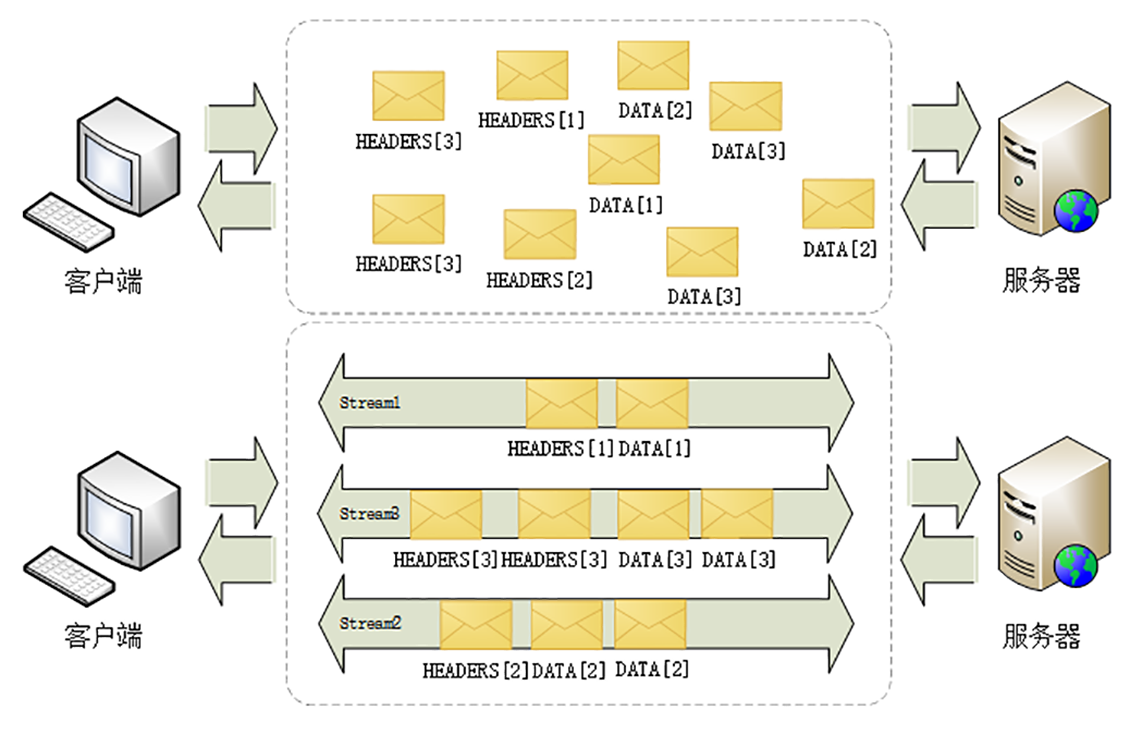
流与多路复用
在 HTTP/2 连接上,虽然帧是乱序收发的,但只要它们都拥有相同的流 ID,就都属于一个流,而且在这个流里帧不是无序的,而是有着严格的先后顺序。
HTTP/2 的流有哪些特点呢?我给你简单列了一下
- 流是可并发的,一个 HTTP/2 连接上可以同时发出多个流传输数据,也就是并发多请求,实现“多路复用”;
- 客户端和服务器都可以创建流,双方互不干扰;
- 流是双向的,一个流里面客户端和服务器都可以发送或接收数据帧,也就是一个“请求 - 应答”来回;
- 流之间没有固定关系,彼此独立,但流内部的帧是有严格顺序的;
- 流可以设置优先级,让服务器优先处理,比如先传 HTML/CSS,后传图片,优化用户体验;
- 流 ID 不能重用,只能顺序递增,客户端发起的 ID 是奇数,服务器端发起的 ID 是偶数;
- 在流上发送“RST_STREAM”帧可以随时终止流,取消接收或发送;
- 第 0 号流比较特殊,不能关闭,也不能发送数据帧,只能发送控制帧,用于流量控制。
- 使用流收发数据,本身就是长连接
- 下载的时候,不需要断开链接,只要简单发送RST_STREAM终止就可以了
- 因为客户端和服务器两端都可以创建流,而流 ID 有奇数偶数和上限的区分,所以大多数的流 ID 都会是奇数,而且客户端在一个连接里最多只能发出 2^30,也就是 10 亿个请求。
- ID 用完了该怎么办呢?这个时候可以再发一个控制帧“GOAWAY”,真正关闭 TCP 连接。
流状态转换
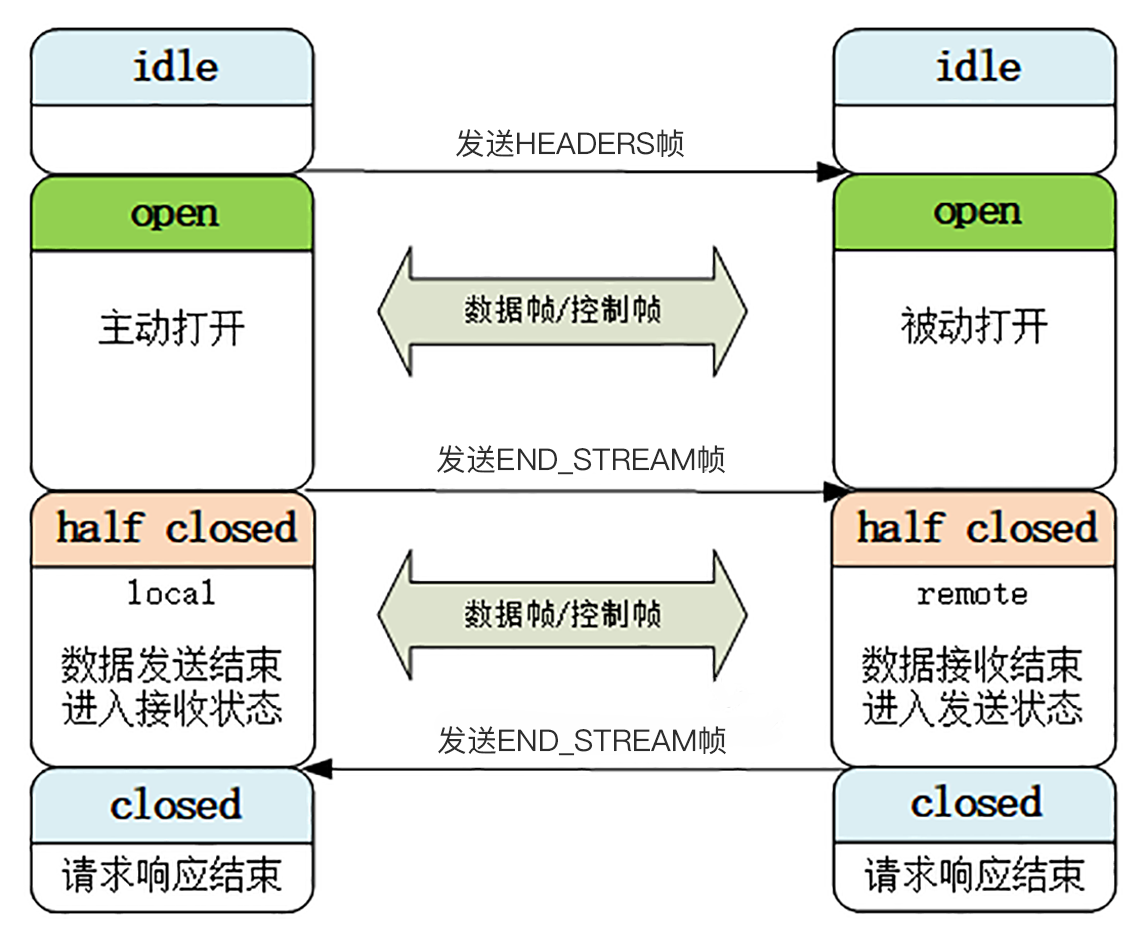
- 空闲状态,也就是“不存在”,可以理解成是待分配的“号段资源”。
- 当客户端发送 HEADERS 帧后,有了流 ID,流就进入了“打开”状态,两端都可以收发数据,然后客户端发送一个带“END_STREAM”标志位的帧,流就进入了“半关闭”状态。这个“半关闭”状态很重要,意味着客户端的请求数据已经发送完了,需要接受响应数据,而服务器端也知道请求数据接收完毕,之后就要内部处理,再发送响应数据。
- 响应数据发完了之后,也要带上“END_STREAM”标志位,表示数据发送完毕,这样流两端就都进入了“关闭”状态,流就结束了。
- 刚才也说过,流 ID 不能重用,所以流的生命周期就是 HTTP/1 里的一次完整的“请求 - 应答”,流关闭就是一次通信结束。
- 下一次再发请求就要开一个新流(而不是新连接),流 ID 不断增加,直到到达上限,发送“GOAWAY”帧开一个新的 TCP 连接,流 ID 就又可以重头计数。